溶岩、噴煙、機械学習 (翻訳記事)
最近、私は Maxarのクラウドベースの地理空間情報クラウド(GBDX)から WorldView2 画像をダウンロードしました。偶然にも、ダウンロードした画像は、最近噴火していたハワイのキラウエア上でした。これに加えて、この画像が観測された日(2018年5月23日)は噴火が活発だったので、画像を見て噴火が強力で破壊的だったかを知ることができました。火山真上画像のサブセットは、次のようになっています。

参考までに、元画像の概要を示す地図上位置のスクリーンショットを以下に示します。
最初に画像を見たとき被害とは別に、ENVIで有意義な解析と分類子を作成することができるようになるとは考えていませんでした。もともと、画像のRGBバンドを調べていただけでしたが、赤外カラーに切り替えて溶岩流の隣にある植生を見ようとしたとき、溶岩の一部が明るくなっていることに気付きました。

このカラーの組み合わせの画像を見て、より長波長の色の組み合わせで、他に何が出現するかを見てみることにしました。WorldView-2データを使用していたため、8つのバンドの中からNIRで2バンド、RedEdgeで1バンドを選択できました。NIR2(950 nm)、NIR1(833 nm)、RE(725 nm)をRGBに割り当てて調べると、溶岩が見えるようになりました!

このイメージを見た後、溶けだした溶岩、冷えた溶岩、放出されたガスのプルーム位置を抽出することができるのではと考えました。今回は、最先端の機械学習アルゴリズムを使ってこれを見てみることにしました。マシンラーニング分類器を作成するためのワークフローは、次のようになります。
- トレーニングデータの抽出
- 分類器を生成する
- 分類器を画像に適用し、必要に応じ、パフォーマンスに基づいてトレーニングデータを反復処理する
今まで分類器を作成したことがある方は、使用している機能やアルゴリズムによっては、1番目と3番目のステップに非常に時間がかかることはご存知でしょう。ENVIでは、ほんの数分でトレーニングデータを抽出し、データの分類器を生成することができます。これに加えて、ピクセルベースの機械学習アルゴリズムの中には、分類の変動が大きい場合でも(この例のように)、衛星、航空、UAVデータ収集プラットフォームで非常に堅牢で優れたパフォーマンスを発揮するものがあります。アルゴリズムを説明する前に、今回使用した DititalGlobe の画像から求めている情報を抽出するための技術について簡単に説明します。
- ENVI + IDL:一般的なファイル I/O とデータ校正。ラジオメトリック校正、パンシャープニング、およびQUACを使用した大気補正にも使用されます。
- IDL-Python Bridge: scikit-learn の機械学習アルゴリズムをENVIに統合する技術を有効にします。
- Python:scikit-learn で利用可能なオープンソースマシン学習アルゴリズムのコアインターフェース
これらのツールを使用して、ランダムフォレスト分類法の、Extra Trees分類器を作成することができました。Extra Treesの詳細は以下のリンクをご覧ください。
Extra Trees: http://scikit-learn.org/stable/modules/ensemble.html#extremely-randomized-trees
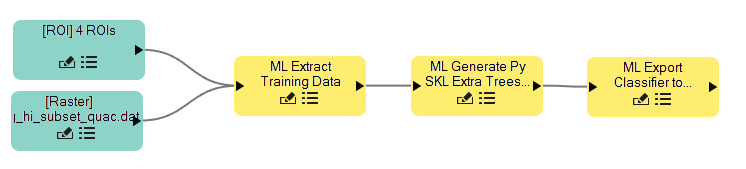
Extra Treesは、非常に高速で、マルチスレッドに対応、簡単に実行できます(ソリューションに合わせて微調整することができる2つのパラメータがあります)。画像分類のためのデシジョンツリーアルゴリズムを好む理由の1つは、手法が繰り返し計算を必要としないということです。ニューラルネットワーク分類法の大部分は、分類器を訓練する必要があり、エポックまたは反復の数を決定する必要があります。これはトレーニングデータの作成に非常に長い時間がかかり、多くのパラメータを調整する必要があります。生成したいアルゴリズムを決定したら、IDLでENVIタスクAPIを使用して、関心領域からデータを選択し、分類器を作成し、ラスタを分類するタスクを抽出しました。分類器生成では、上記のリストからステップ1 + 2を持つかのような ENVI Modelerの単純なワークフローを次に示します。
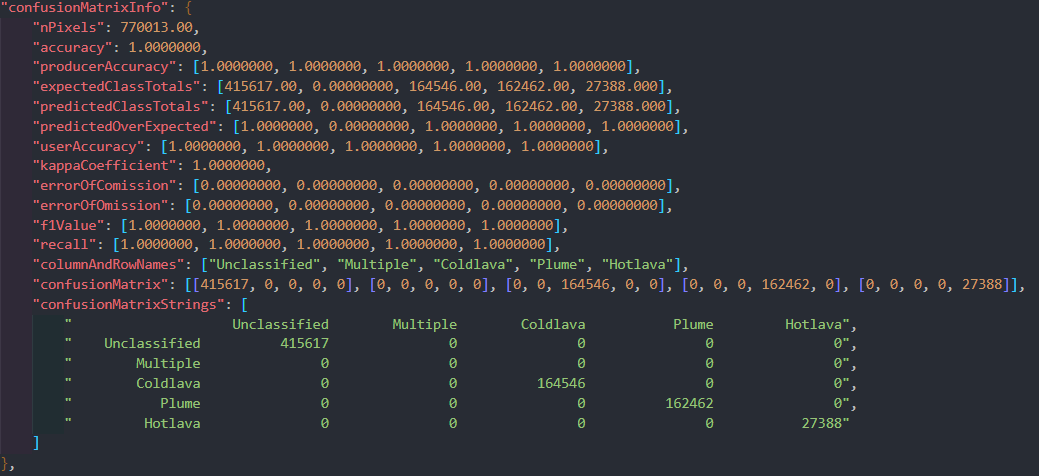
ワークフローが終了すると、分類器とJSONファイルの2つの出力が得られます。JSONファイルには、トレーニングデータの正確度に関するメトリックを含む分類器の説明が含まれています。この例では、トレーニングデータに 770,013 ピクセルありました。驚くべきことに、Extra Trees 分類器は**各ピクセルを正しく**分類しました。ここでは、それがどれくらいうまく実行されたかを示す混同行列情報を見ていきます。
分類器が生成されたので、次に、単一のENVIタスクを使用する元のラスタを分類します。合計で、このシーンでは、私のマシンで約2.8 GBの画像を分類するのにおよそ10分かかりました。一度分類されても、ワークフローが完全に終了したわけではありません。我々はそれをさらに一歩踏み出して、結果からいくつかの意味のある情報を抽出するつもりです。具体的には、溶岩プルーム(火山ガス)までの距離に関する近接地図を作成します。これを実現するには、バッファーゾーンタスク(ENVI 5.5.1の新機能)とラスターカラースライスを使用して距離情報を抽出します。分類結果と近接マップの最終結果は、次のようになります。
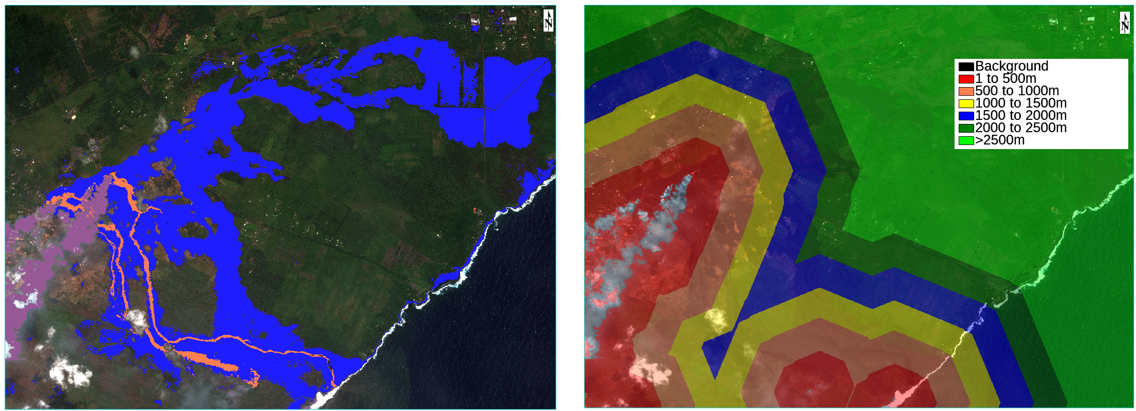
左の分類結果を見ると、分類処理で特徴ある部分を抽出できていることが分かります。改善できるかもしれない領域は、噴煙が目視で見えるほど厚くない領域を抽出しようとしている部分です。注目すべき部分は、雲と噴煙が分類されており、それらが互いにスペクトル的に異なることを示していることです。
この内容は、2018年11月13日の Zachary Norman による英文記事の翻訳です。
原文:https://www.nv5geospatialsoftware.com/Learn/Blogs/Blog-Details/ArtMID/10198/ArticleID/23557/Lava-Plumes-and-Machine-Learning-Oh-My